分类
商品






















![[ JS系列5 ] 可选的分号](https://pic.songma.com/wenzhang/20180606/cvzrdb3n0vf4157.jpg "[ JS系列5 ] 可选的分号")


- 商品
- 店铺
- 资讯
面试题1:说一下 HashMap 的实现原理?
面试题2:HashMap是线程安全的吗?
追问3:ConcurrentHashMap在JDK1.7、1.8中都有哪些优化?
 image.png
image.png正经答复:
众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry(包括Key-Value),其中Key 和 Value 允许为null。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。另外,HashMap数组每一个元素的初始值都是Null。
 image
image值得注意的是:HashMap不能保证映射的顺序,插入后的数据顺序也不能保证一直不变(如扩容后rehash)。
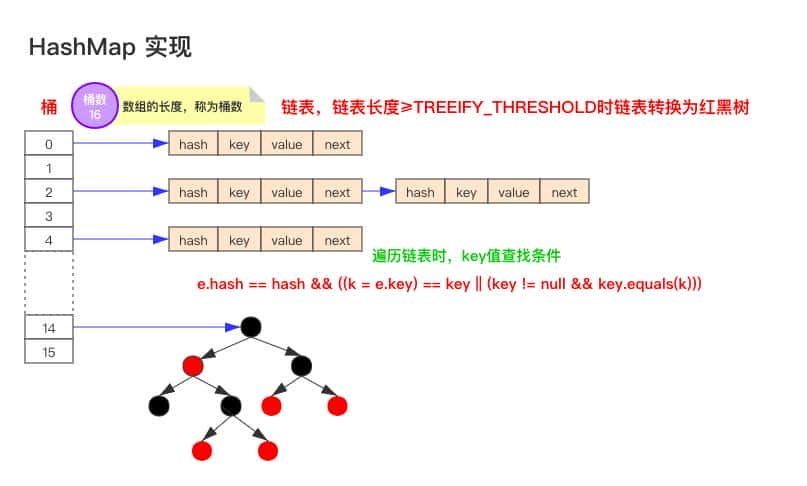
要说HashMap的原理,首先要先理解它的数据结构
 image
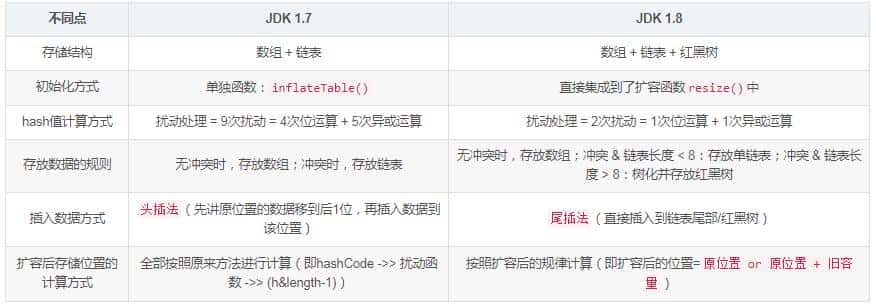
image如上图为JDK1.8版本的数据结构,其实HashMap在JDK1.7及以前是一个“链表散列”的数据结构,即数组 + 链表的结合体。JDK8优化为:数组+链表+红黑树。
我们常把数组中的每一个节点称为一个桶。当向桶中增加一个键值对时,首先计算键值对中key的hash值(hash(key)),以此确定插入数组中的位置(即哪个桶),但是可能存在同一hash值的元素已经被放在数组同一位置了,这种现象称为碰撞,这时按照尾插法(jdk1.7及以前为头插法)的方式增加key-value到同一hash值的元素的最后面,链表就这样形成了。
当链表长度超过8(TREEIFY_THRESHOLD - 阈值)时,链表就自行转为红黑树。
注意:同一hash值的元素指的是key内容一样么?不是。根据hash算法的计算方式,是将key值转为一个32位的int值(近似取值),key值不同但key值相近的很可能hash值相同,如key=“a”和key=“aa”等
通过上述答复的内容,我们显著给了面试官往深入问的多个诱饵,根据我们的答复,下一步他多可能会追问这些问题:
1、如何实现HashMap的有序?
4、put方法原理是怎样实现的?
6、扩容机制原理 → 初始容量、加载因子 → 扩容后的rehash(元素迁移)
2、插入后的数据顺序会变的起因是什么?
3、HashMap在JDK1.7-JDK1.8都做了哪些优化?
5、链表红黑树如何互相转换?阈值多少?
7、头插法改成尾插法为理解决什么问题?
而我们,当然是提前准备好如何答复好这些问题!当你的答复超过面试同学的认知范围时,主动权就到我们手里了。
 image
image使用LinkedHashMap 或者 TreeMap。
LinkedHashMap内部维护了一个单链表,有头尾节点,同时LinkedHashMap节点Entry内部除了继承HashMap的Node属性,还有before 和 after用于标识前置节点和后置节点。可以实现按插入的顺序或者访问顺序排序。
/** * The head (eldest) of the doubly linked list.*/transient LinkedHashMap.Entry<K,V> head;/** * The tail (youngest) of the doubly linked list.*/transient LinkedHashMap.Entry<K,V> tail;//将加入的p节点增加到链表末尾private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail; tail = p; if (last == null) head = p; else { p.before = last; last.after = p; }}//LinkedHashMap的节点类static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); }}示例代码:
public static void main(String[] args) { Map<String, String> linkedMap = new LinkedHashMap<String, String>(); linkedMap.put("1", "占便宜"); linkedMap.put("2", "没够儿"); linkedMap.put("3", "吃亏"); linkedMap.put("4", "难受"); for(linkedMap.Entry<String,String> item: linkedMap.entrySet()){ System.out.println(item.getKey() + ":" + item.getValue()); }}输出结果:
1:占便宜2:没够儿3:吃亏4:难受TreeMap是按照Key的自然顺序或者者Comprator的顺序进行排序,内部是通过红黑树来实现。
TreeMap<String, String> map = new TreeMap<String, String>(new Comparator<String>() { @Override public int compare(String o1, String o2) { return o2.compareTo(o1); }});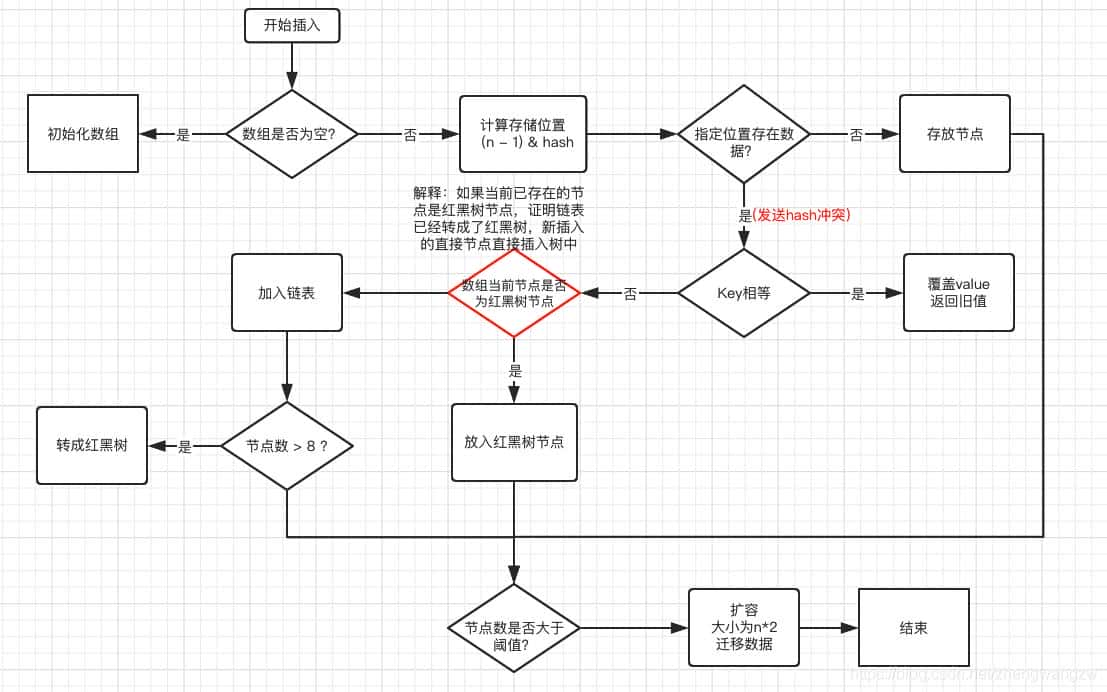 image
image因而,在扩容时,不需要重新计算元素的hash了,只要要判断最高位是1还是0就好了。
下面我们看看源码中的内容:
/** * 将指定参数key和指定参数value插入map中,假如key已经存在,那就替换key对应的value * * @param key 指定key * @param value 指定value * @return 假如value被替换,则返回旧的value,否则返回null。当然,可能key对应的value就是null。 */public V put(K key, V value) { //putVal方法的实现就在下面 return putVal(hash(key), key, value, false, true);}从源码中可以看到,put(K key, V value)可以分为三个步骤:
那么看看putVal方法的源码是如何实现的?
/** * Map.put和其余相关方法的实现需要的方法 * * @param hash 指定参数key的哈希值 * @param key 指定参数key * @param value 指定参数value * @param onlyIfAbsent 假如为true,即便指定参数key在map中已经存在,也不会替换value * @param evict 假如为false,数组table在创立模式中 * @return 假如value被替换,则返回旧的value,否则返回null。当然,可能key对应的value就是null。 */final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //假如哈希表为空,调用resize()创立一个哈希表,并用变量n记录哈希表长度 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //假如指定参数hash在表中没有对应的桶,即为没有碰撞 if ((p = tab[i = (n - 1) & hash]) == null) //直接将键值对插入到map中就可 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; //假如碰撞了,且桶中的第一个节点就匹配了 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) //将桶中的第一个节点记录起来 e = p; //假如桶中的第一个节点没有匹配上,且桶内为红黑树结构,则调用红黑树对应的方法插入键值对 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //不是红黑树结构,那么就一定是链式结构 else { //遍历链式结构 for (int binCount = 0; ; ++binCount) { //假如到了链表尾部 if ((e = p.next) == null) { //在链表尾部插入键值对 p.next = newNode(hash, key, value, null); //假如链的长度大于TREEIFY_THRESHOLD这个临界值,则把链变为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); //跳出循环 break; } //假如找到了重复的key,判断链表中结点的key值与插入的元素的key值能否相等,假如相等,跳出循环 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表 p = e; } } //假如key映射的节点不为null if (e != null) { // existing mapping for key //记录节点的vlaue V oldValue = e.value; //假如onlyIfAbsent为false,或者者oldValue为null if (!onlyIfAbsent || oldValue == null) //替换value e.value = value; //访问后回调 afterNodeAccess(e); //返回节点的旧值 return oldValue; } } //结构型修改次数+1 ++modCount; //判断能否需要扩容 if (++size > threshold) resize(); //插入后回调 afterNodeInsertion(evict); return null;}capacity 即容量,默认16。
loadFactor 加载因子,默认是0.75threshold 阈值。阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容。
这里我们以JDK1.8的扩容为例:
HashMap的容量变化通常存在以下几种情况:
此外还有几个点需要注意:
扩容时,要扩大空间,为了使hash散列均匀分布,原有部分元素的位置会发生移位。
JDK7的元素迁移
JDK7中,HashMap的内部数据保存的都是链表。因而逻辑相对简单:在准备好新的数组后,map会遍历数组的每个“桶”,而后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
这里有几个注意点:
JDK1.8的元素迁移
JDK1.8则由于巧妙的设计,性能有了大大的提升:因为数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。起因如下图:
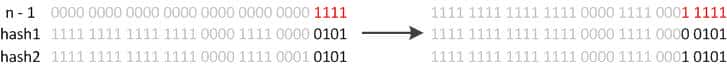 image
image数组长度变为原来的2倍,体现在二进制上就是多了一个高位参加数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,刚好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:
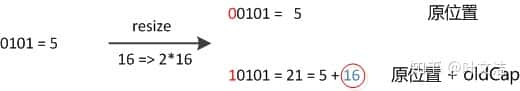 image
image因而,在扩容时,不需要重新计算元素的hash了,只要要判断最高位是1还是0就好了。
JDK8的HashMap还有以下细节需要注意:
 image
image防止发生hash冲突,链表长渡过长,将时间复杂度由O(n)降为O(logn);
由于1.7头插法扩容时,头插法可能会导致链表发生反转,多线程环境下会产生环(死循环);
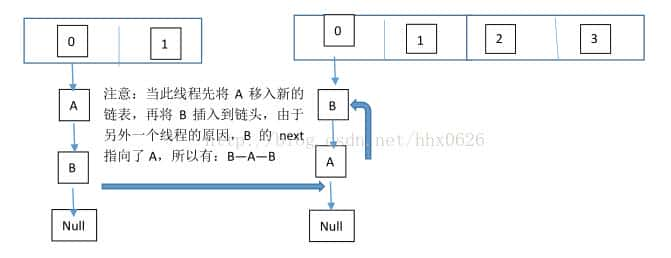 image
image这个过程为,先将A复制到新的hash表中,而后接着复制B到链头(A的前边:B.next=A),原本B.next=null,到此也就结束了(跟线程二一样的过程),但是,因为线程二扩容的起因,将B.next=A,所以,这里继续复制A,让A.next=B,由此,环形链表出现:B.next=A; A.next=B
使用头插会改变链表的上的顺序,但是假如使用尾插,在扩容时会保持链表元素本来的顺序,就不会出现链表成环的问题了。
就是说本来是A->B,在扩容后那个链表还是A->B。
经过计算,在hash函数设计正当的情况下,发生hash碰撞8次的几率为百万分之6,从概率上讲,阈值为8足够用;至于为什么红黑树转回来链表的条件阈值是6而不是7或者9?由于假如hash碰撞次数在8周围徘徊,可能会频繁发生链表和红黑树的互相转化操作,为了预防这种情况的发生。
不是线程安全的,在多线程环境下,
以1.8为例,当A线程判断index位置为空后正好挂起,B线程开始往index位置写入数据时,这时A线程恢复,执行写入操作,这样A或者B数据就被覆盖了。
在Java中有HashTable、SynchronizedMap、ConcurrentHashMap这三种是实现线程安全的Map。
在并发编程中使用HashMap可能导致程序死循环。而使用线程安全的HashTable效率又非常低下,基于以上两个起因,便有了ConcurrentHashMap的登场机会
1)线程不安全的HashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。HashMap在并发执行put操作时会引起死循环,是由于多线程环境下会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,调用.next()时就会产生死循环获取Entry。
2)效率低下的HashTable
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下(相似于数据库中的串行化隔离级别)。由于当一个线程访问HashTable的同步方法,其余线程也访问HashTable的同步方法时,会进入阻塞或者轮询状态。如线程1使用put进行元素增加,线程2不但不能使用put方法增加元素,也不能使用get方法来获取元素,读写操作均需要获取锁,竞争越激烈效率越低。
因而,若未明确严格要求业务遵循串行化时(如转账、支付类业务),建议不启用HashTable。
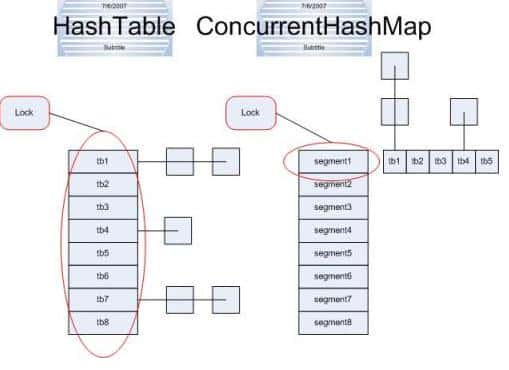 image
image3)ConcurrentHashMap的分段锁技术可有效提升并发访问率
HashTable容器在竞争激烈的并发环境下体现出效率低下的起因是所有访问HashTable的线程都必需竞争同一把锁,如果容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在严重锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的分段锁技术。首先将数据分成一段一段地存储(一堆Segment),而后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其余段的数据也能被其余线程访问。
对于 ConcurrentHashMap 你至少要知道的几个点:
其实,JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是添加了同步的操作来控制并发。
从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
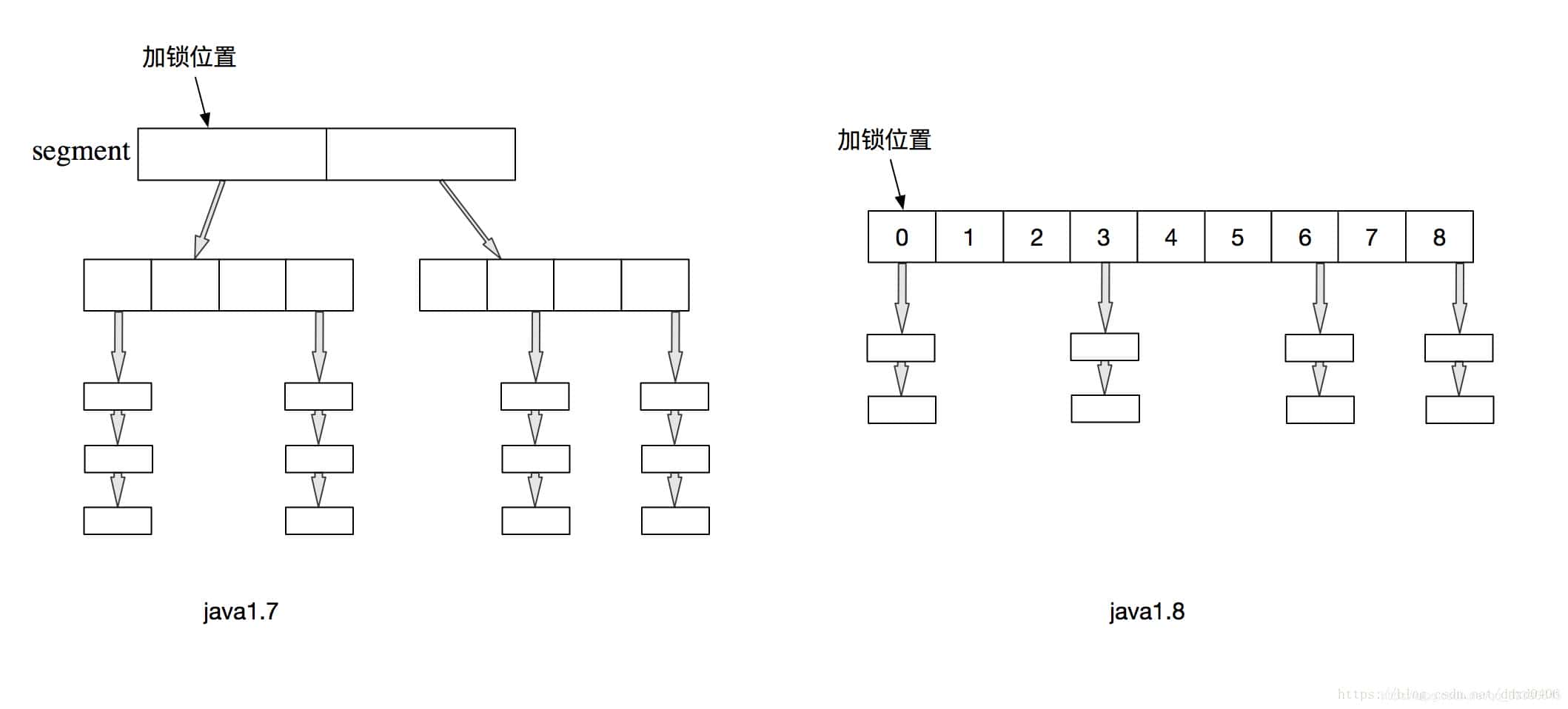 image
image数据结构上跟HashMap很像,从1.7到1.8版本,因为HashEntry从链表 → 红黑树所以 concurrentHashMap的时间复杂度从O(n)到O(log(n)) ↓↓↓;
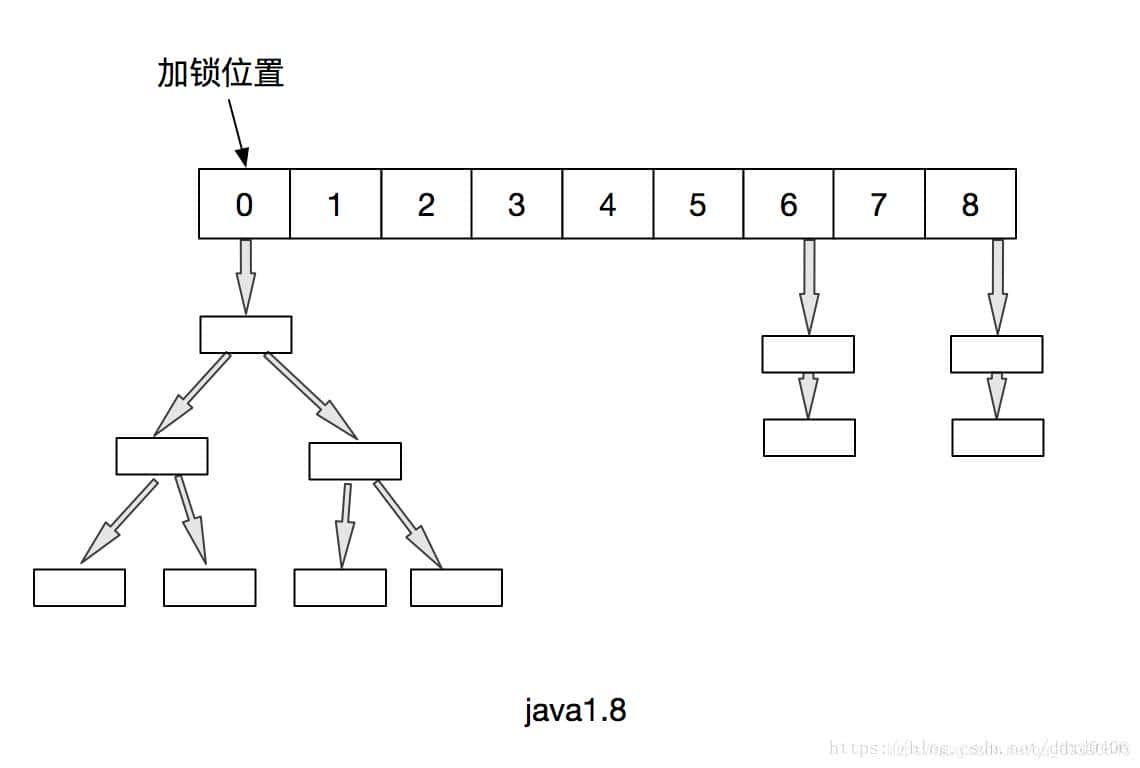 image
image同时,也把之前的HashEntry改成了Node,作用不变,当Node链表的节点数大于8时Node会自动转化为TreeNode,会转换成红黑树的结构。把值和next采用了volatile去修饰,保证了可见性,并且也引入了红黑树,在链表大于肯定值的时候会转换(默认是8)。
归纳一下:
作者:_陈哈哈
原文链接:https://blog.csdn.net/qq_39390545/article/details/118077143

 ¥40.00
¥40.00
(自适应手机版)响应式营销型恒温恒湿机环境设施类网站模板蓝色营销型空调设施网站源
 ¥40.00
¥40.00
(自适应手机版)响应式代理商记账财政咨询服务类pbootcms网站模板H5财务会计类网站源码
 ¥69.00
¥69.00
(自适应手机版)绿色清新的宠物门诊医院pbootcms网站模板 大气简洁的宠物店兽医网站源码
 ¥69.00
¥69.00
(自适应手机版)html5响应式二极管LED灯具类pbootcms模板 LED灯具网站源码
 ¥69.00
¥69.00
(自适应手机版)响应式机械阀门设施类网站pbootcms模板 红色五金机械网站源码
 ¥69.00
¥69.00
(自适应手机版)响应式电梯扶梯类pbootcms模板 电梯生产企业绿色企业网站源码

送码官方微信





![[SLG/PC+安卓] 龙之女 Daughters of the Dragon v0.194[470MB]](https://img.songma.com/upload/156100/1746426367-156100/0525576001746426398tp156100-1.jpg)












 属性代理商Property Delegates")







 手机访问领取大礼包
手机访问领取大礼包