分类
商品






















![[ JS系列5 ] 可选的分号](https://pic.songma.com/wenzhang/20180606/cvzrdb3n0vf4157.jpg "[ JS系列5 ] 可选的分号")


- 商品
- 店铺
- 资讯
回顾一下发现本科学的东西都忘了,网络如同是那个说脏话的爱尔兰人教的,总之脑子里全是烤羊腿和老雪。这里重新整理一下。
内容:
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC (Request for Comments) 2616定义了今天普遍使用的一个版本——HTTP 1.1。 http/1.0 和 http/1.1 还是有很显著的区别的。后面再说
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。(和网页的内容的体现形式有关,图片是通过url来定位的,文字先加载,图片再一次http请求,加载得到之后再加载)
HTTP是一个应用层协议,由请求和响应构成,是一个标准的用户端服务器模型。HTTP是一个无状态的协议。(<mark>无状态指的是状态无记录,通过session或者者cooki这种东西来实现有状态</mark>)
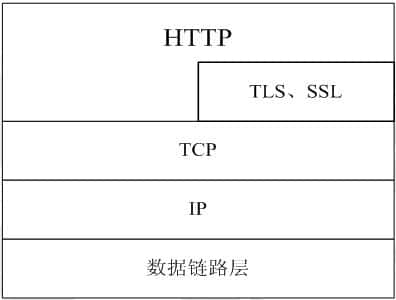
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或者SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图所示:
 https
https<mark>默认HTTP的端口号为80,HTTPS的端口号为443</mark>.
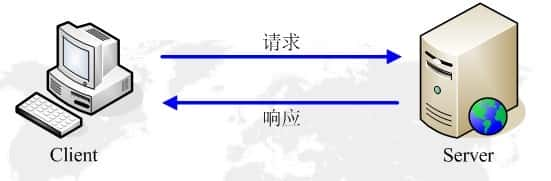
HTTP协议永远都是用户端发起请求,服务器回送响应。见下图:
 http-client-server-model
http-client-server-model这样就限制了使用HTTP协议,无法实现在用户端没有发起请求的时候,服务器将消息推送给用户端。
HTTP协议是一个无状态的协议,同一个用户端的这次请求和上次请求是没有对应关系。
一次HTTP操作称为一个事务,其工作过程可分为四步:
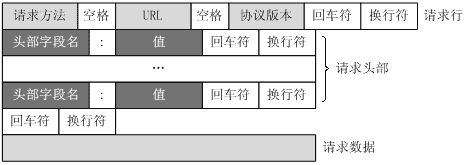
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成,下图给出了请求报文的一般格式。
 https
https请求行 请求行分为三个部分:请求方法、请求地址 和 协议版本.
请求方法:
HTTP/1.1 定义的请求方法有8种:GET、POST、PUT、DELETE、PATCH、HEAD、OPTIONS、TRACE。
最常的两种GET和POST,假如是RESTful接口的话一般会用到GET、POST、DELETE、PUT。HTTP/1.0 只定义了三种 GET, HEAD, POST
请求地址:
URL:统一资源定位符,是一种自愿位置的笼统唯一识别方法。
组成:<协议>://<主机>:<端口>/<路径>
端口和路径有时可以省略(HTTP默认端口号是80)
如下例:
 https
https协议版本:
协议版本的格式为:HTTP/主版本号.次版本号,常用的有HTTP/1.0和HTTP/1.1
请求头部
请求头部为请求报文增加了少量附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
常见请求头如下:
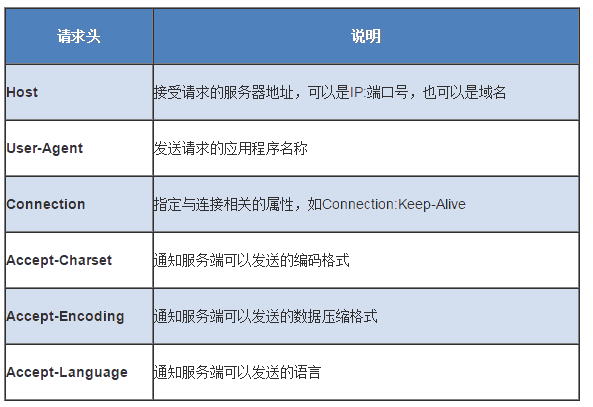 https
https请求头部的最后会有一个空行,表示请求头部结束,接下来为请求数据,这一行非常重要,必不可少。
请求数据
可选部分,比方GET请求一般就没有请求数据。
下面是一个POST方法的请求报文:
POST /index.php HTTP/1.1 请求行Host: localhostUser-Agent: Mozilla/5.0 (Windows NT 5.1; rv:10.0.2) Gecko/20100101 Firefox/10.0.2 请求头Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8Accept-Language: zh-cn,zh;q=0.5Accept-Encoding: gzip, deflateConnection: keep-aliveReferer:http://localhost/Content-Length:25Content-Type:application/x-www-form-urlencoded //空行//username=aa&password=1234 请求数据HTTP响应报文由状态行、响应头部、空行以及响应数据组成。
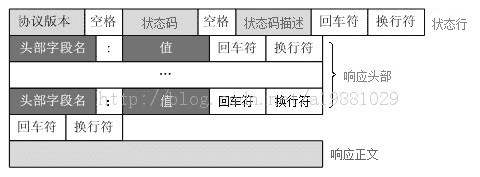 https
https状态行
由3部分组成,分别为:协议版本,状态码,状态码形容 三个。
其中协议版本与请求报文一致,状态码形容是对状态码的简单形容。
-状态码:
状态代码为3位数字。
1xx:指示信息——表示请求已接收,继续解决。
2xx:成功——表示请求已被成功接收、了解、接受。
3xx:重定向——要完成请求必需进行更进一步的操作。
4xx:用户端错误——请求有语法错误或者请求无法实现。
5xx:服务器端错误——服务器未能实现合法的请求。
-协议版本:
协议版本的格式为:HTTP/主版本号.次版本号,常用的有HTTP/1.0和HTTP/1.1
据两个例子:
HTTP/1.1 200 OKHTTP/1.1 200 Connection established响应头部
与请求头部相似,为响应报文增加了少量附加信息
常见响应头部如下:
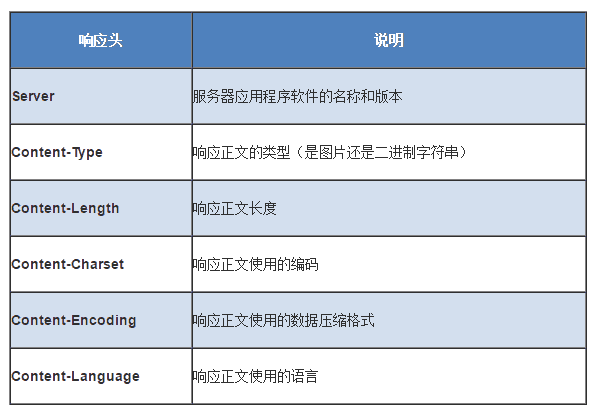 常见响应头
常见响应头请求头部的最后会有一个空行,表示请求头部结束,接下来为请求数据,这一行非常重要,必不可少。
响应数据
用于存放需要返回给用户端的数据信息。
下面是一个响应报文的实例:
HTTP/1.1 200 OK 状态行Server: Tengine/2.0.2 响应头部Date: Thu, 13 Sep 2018 11:17:28 GMTContent-Type: text/html;charset=UTF-8Transfer-Encoding: chunkedX-ASEN: SEN-9877428Cache-Control: no-cache, must-revalidateExpires: Thu, 01 Jan 1970 00:00:00 GMTX-Confluence-Request-Time: 1536837448721X-Seraph-LoginReason: OKX-AUSERNAME: zhangyu02_sxX-XSS-Protection: 1; mode=blockX-Content-Type-Options: nosniffX-Frame-Options: SAMEORIGINContent-Security-Policy: frame-ancestors 'self'Proxy-Connection: keep-alive-----空行----- <!DOCTYPE html> 响应数据<html> ....... </html>通用首部字段(General Header Fields)
请求报文和响应报文两方都会使用的首部。请求首部字段(Request Header Fields)
从用户端向服务器端发送请求报文时使用的首部。补充了请求的附加内容、用户端信息、响应内容相关优先级等信息。响应首部字段(Response Header Fields)
从服务器端向用户端返回响应报文时使用的首部。补充了响应的附加内容,也会要求用户端附加额外的内容信息。实体首部字段(Entity Header Fields)
针对请求报文和响应报文的实体部分使用的首部。补充了资源内容升级时间等与实体有关的信息。
通用首部字段
| 首部字段名 | 说明 |
|---|
Cache-Control |控制缓存的行为
Connection |逐跳首部、连接的管理
Date |创立报文的日期时间
Pragma |报文指令
Trailer |报文末端的首部一览
Transfer-Encoding| 指定报文主体的传输编码方式
Upgrade |更新为其余协议
Via |代理商服务器的相关信息
Warning |错误通知
请求首部字段...
响应首部字段...
实体首部字段
首部字段名 |说明
---------|------
Allow |资源可支持的HTTP方法
Content-Encoding| 实体主体适用的编码方式
Content-Language| 实体主体的自然语言
Content-Length |实体主体的大小(单位:字节)
Content-Location| 替代对应资源的URI
Content-MD5 |实体主体的报文摘要
Content-Range |实体主体的位置范围
Content-Type |实体主体的媒体类型
Expires |实体主体过期的日期时间
Last-Modified |资源的最后修改日期时间
HTTP/1.0 每次请求都需要建立新的TCP连接,连接不能复用。HTTP/1.1 新的请求可以在上次请求建立的TCP连接之上发送,连接可以复用。优点是减少重复进行TCP三次握手的开销,提高效率。
<mark>注意:在同一个TCP连接中,新的请求需要等上次请求收到响应后,才能发送。</mark>
这是由于,
在http1.1,request和reponse头中都有可能出现一个connection的头,此header的含义是当client和server通信时对于长链接如何进行解决。
在http1.1中,client和server都是默认对方支持长链接的, 假如client使用http1.1协议,但又不希望使用长链接,则需要在header中指明connection的值为close;假如server方也不想支持长链接,则在response中也需要明确说明connection的值为close。不管request还是response的header中包含了值为close的connection,都表明当前正在使用的tcp链接在当前请求解决完毕后会被断掉。以后client再进行新的请求时就必需创立新的tcp链接了。
HTTP1.1在Request消息头里头多了一个Host域, HTTP1.0则没有这个域。
Eg.:
GET /pub/WWW/TheProject.html HTTP/1.1 Host: www.w3.org可能HTTP1.0的时候认为,建立TCP连接的时候已经指定了IP地址,这个IP地址上只有一个host。
(接收方向)
无论是HTTP1.0还是HTTP1.1,都要能解析下面三种date/time stamp:
Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822, updated by RFC 1123
Sunday, 06-Nov-94 08:49:37 GMT ; RFC 850, obsoleted by RFC 1036
Sun Nov 6 08:49:37 1994 ; ANSI C's asctime() format
(发送方向)
HTTP1.0要求不能生成第三种asctime格式的date/time stamp;
HTTP1.1则要求只生成RFC 1123(第一种)格式的date/time stamp。
状态响应码100 (Continue) 状态代码的使用,允许用户端在发request消息body之前先用request header试探一下server,看server要不要接收request body,再决定要不要发request body。
用户端在Request头部中包含
Expect: 100-continueServer看到之后呢假如回100 (Continue) 这个状态代码,用户端就继续发request body。这个是HTTP1.1才有的。
另外在HTTP/1.1中还添加了101、203、205等等性状态响应码
HTTP1.1添加了OPTIONS, PUT, DELETE, TRACE, CONNECT这些Request方法
Cookie和Session都为了用来保存状态信息,都是保存用户端状态的机制,它们都是为理解决HTTP无状态的问题而所做的努力。
Session可以用Cookie来实现,也可以用URL回写的机制来实现。用Cookie来实现的Session可以认为是对Cookie更高级的应用。
Cookie和Session有以下显著的不同点:
1)Cookie将状态保存在用户端,Session将状态 保存在服务器端;
2)Cookies是服务器在 本地机器上存储的小段文本 并随每一个请求发送至同一个服务器。
Cookie最早在RFC2109中实现,后续RFC2965做了加强。网络服务器用HTTP头向用户端发送cookies,在用户终端,浏览器解析这些cookies并将它们保存为一个本地文件,它会自动将同一服务器的任何请求缚上这些cookies。Session并没有在HTTP的协议中定义;
3)Session是针对每一个客户的,变量的值保存在服务器上,用一个sessionID来区分是哪个客户session变量,这个值是通过客户的浏览器在访问的时候返回给服务器,当用户禁用cookie时,这个值也可可设置为由get来返回给服务器;
4)就安全性来说:当你访问一个使用session 的站点,同时在自己机子上建立一个cookie,建议在服务器端的SESSION机制更安全些.由于它不会任意读取用户存储的信息。
Session机制是一种服务器端的机制,服务器使用一种相似于散列表的结构(也可能就是使用散列表)来保存信息。
当程序需要为某个用户端的请求创立一个session的时候,服务器首先检查这个用户端的请求里能否已包含了一个session标识 - 称为 session id,假如已包含一个session id, 则说明以前已经为此用户端创立过session,服务器就按照session id 把这个 session 检索出来使用(假如检索不到,可能会新建一个),假如用户端请求不包含session id,则为此用户端创立一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个 session id将被在本次响应中返回给用户端保存。
使用Cookie来实现
服务器给每个Session分配一个唯一的JSESSIONID,并通过Cookie发送给用户端。
当用户端发起新的请求的时候,将在Cookie头中携带这个JSESSIONID。这样服务器能够找到这个用户端对应的Session。
流程如下图所示:
 使用cooki实现session
使用cooki实现session使用URL回显来实现
URL回写是指服务器在发送给浏览器页面的所有链接中都携带JSESSIONID的参数,这样用户端点击任何一个链接都会把JSESSIONID带会服务器。
假如直接在浏览器输入服务端资源的url来请求该资源,那么Session是匹配不到的。
Tomcat对Session的实现,是一开始同时使用Cookie和URL回写机制,假如发现用户端支持Cookie,就继续使用Cookie,中止使用URL回写。假如发现Cookie被禁用,就一直使用URL回写。jsp开发解决到Session的时候,对页面中的链接最好使用response.encodeURL(),起因你懂的。
服务器在响应消息中用Set-Cookie头将Cookie的内容回送给用户端,用户端在新的请求中将相同的内容携带在Cookie头中发送给服务器。从而实现会话的保持。
流程如下图所示:
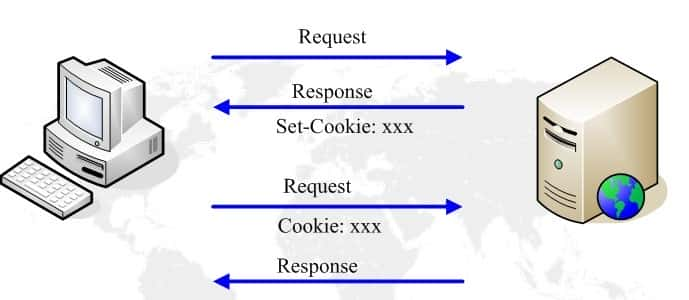 cooki的流程
cooki的流程服务器收到请求时,会在200OK中回送该资源的Last-Modified和ETag头,用户端将该资源保存在cache中,并记录这两个属性。当用户端需要发送相同的请求时,会在请求中携带If-Modified-Since和If-None-Match两个头。两个头的值分别是响应中Last-Modified和ETag头的值。服务器通过这两个头判断本地资源未发生变化,用户端不需要重新下载,返回304响应。常见流程如下图所示:
 用户端缓存生效常见流程
用户端缓存生效常见流程HTTP/1.1中缓存的目的是为了在很多情况下减少发送请求,同时在许多情况下可以不需要发送完整响应。前者减少了网络回路的数量;HTTP利用一个“过期(expiration)”机制来为此目的。后者减少了网络应用的带宽;HTTP用“验证(validation)”机制来为此目的。
HTTP定义了3种缓存机制:
1)Freshness:允许一个回应消息可以在源服务器不被重新检查,并且可以由服务器和用户端来控制。例如,Expires回应头给了一个文档不可用的时间。Cache-Control中的max-age标识指明了缓存的最长时间;
2)Validation:用来检查以一个缓存的回应能否依然可用。例如,假如一个回应有一个Last-Modified回应头,缓存能够使用If-Modified-Since来判断能否已改变,以便判断根据情况发送请求;
3)Invalidation: 在另一个请求通过缓存的时候,常常有一个反作用。例如,假如一个URL关联到一个缓存回应,但是其后跟着POST、PUT和DELETE的请求的话,缓存就会过期。
分块请求资源实例:
E.g.1:Range: bytes=306302- :请求这个资源从306302个字节到末尾的部分;E.g.2:Content-Range: bytes 306302-604047/604048: 响应中指示携带的是该资源的第306302-604047的字节,该资源共604048个字节;用户端通过并发的请求相同资源的不同片段,来实现对某个资源的并发分块下载。从而达到快速下载的目的。目前流行的FlashGet和迅雷基本都是这个原理。
多线程下载的原理:
用户端发起HTTPS请求
这个没什么好说的,就是客户在浏览器里输入一个https网址,而后连接到server的443端口。
服务端的配置
采用HTTPS协议的服务器必需要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要用户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提醒页面(startssl就是个不错的选择,有1年的免费服务)。这套证书其实就是一对公钥和私钥。假如对公钥和私钥不太了解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,而后发给你,由于只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
用户端解析证书
这部分工作是有用户端的TLS来完成的,首先会验证公钥能否有效,比方颁发机构,过期时间等等,假如发现异常,则会弹出一个警告框,提醒证书存在问题。假如证书没有问题,那么就生成一个随即值。而后用证书对该随机值进行加密。就如同上面说的,把随机值用锁头锁起来,这样除非有钥匙,不然看不到被锁住的内容。
传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后用户端和服务端的通信即可以通过这个随机值来进行加密解密了。
服务端加密信息
服务端用私钥解密后,得到了用户端传过来的随机值(私钥),而后把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好用户端和服务端都知道这个私钥,所以只需加密算法够彪悍,私钥够复杂,数据就够安全。
传输加密后的信息
这部分信息是服务段用私钥加密后的信息,可以在用户端被复原
用户端解密信息
用户端用之前生成的私钥解密服务段传过来的信息,于是获取理解密后的内容。
给一张图:
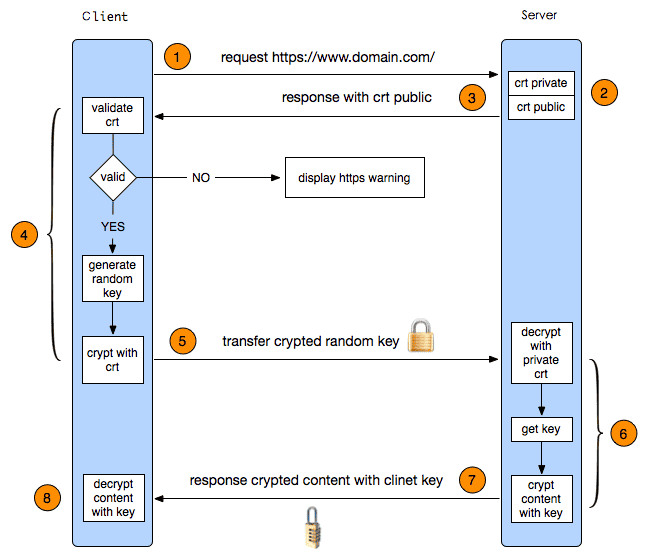 https过程
https过程整个过程第三方即便监听到了数据,也束手无策。
 QRCode
QRCode

送码官方微信





![[SLG/PC+安卓] 龙之女 Daughters of the Dragon v0.194[470MB]](https://img.songma.com/upload/156100/1746426367-156100/0525576001746426398tp156100-1.jpg)












 属性代理商Property Delegates")













 手机访问领取大礼包
手机访问领取大礼包